Über dieses Dokument
1. Einleitung
Regal ist eine Content Repository zur Verwaltung und Veröffentlichung elektronischer Publikationen. Es wird seit 2013 am Hochschulbibliothekszentrum (hbz) entwickelt.
Regal basiert auf den folgenden Kerntechnologien:
-
Fedora Commons 3
-
Elasticsearch 1.1
-
Drupal 7
-
Playframework 2.4
-
MySQL 5
-
Java 8
-
PHP 5
Für die Webarchivierung kommen außerdem Openwayback, Heritrix und WPull zum Einsatz.
-
openwayback hbz-2.3.2
-
heritrix 3.2.0
-
wpull
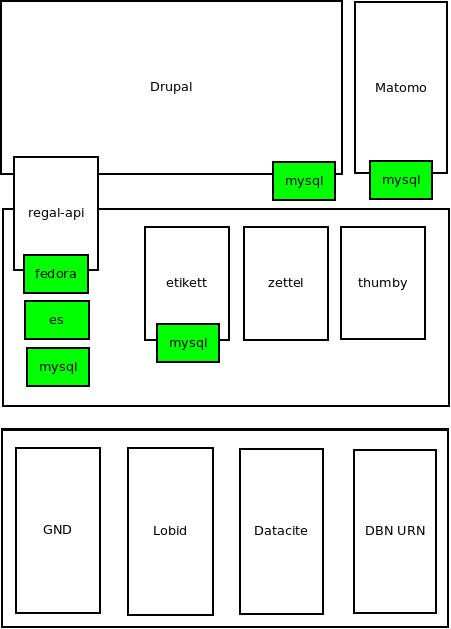
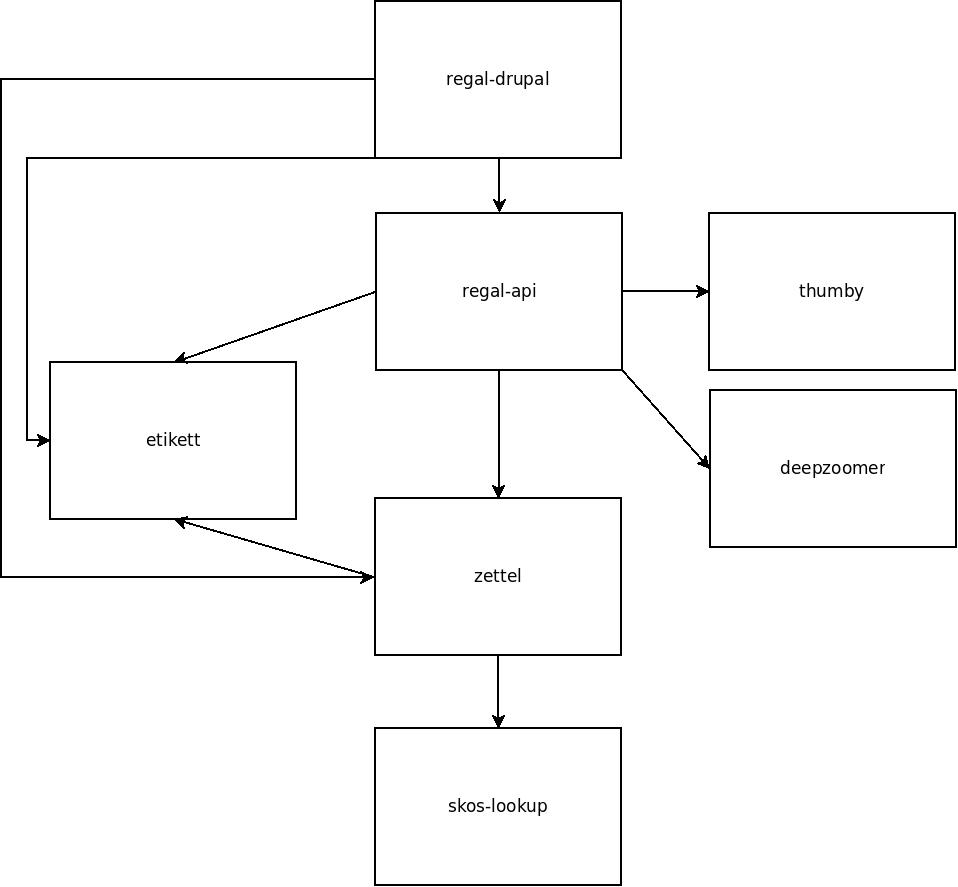
Regal ist ein mehrkomponentiges System. Einzelne Komponenten sind als Webservices realisiert und kommunizieren über HTTP-APIs miteinander. Derzeit sind folgende Komponenten im Einsatz
Drupal Themes
Über die Systemschnittstellen können eine ganze Reihe von Drittsystemen angesprochen werden. Die folgende Abbildung verschafft einen groben Überblick über eine typische Regal-Installation und die angebundenen Drittsysteme.
2. Konzepte
2.1. Objektmodell
Regal realisiert ein einheitliches Objektmodell in dem sich eine Vielzahl von Publikationstypen speichern lassen. Die Speicherschicht wird über Fedora Commons 3 realisiert.
Eine einzelne Publikation besteht i.d.R. aus mehreren Fedora Commons 3-Objekten, die in einer hierarchischen Beziehung zueinander stehen.
| Datenstrom | Pflicht | Beschreibung |
|---|---|---|
DC |
Ja |
Von Fedora vorgeschrieben. Wird für die fedorainterne Suche verwendet |
RELS-EXT |
Ja |
Von Fedora vorgeschrieben. Wird für viele Sachen verwendet - (1) Hierarchien - (2) Steuerung der Sichtbarkeiten - (2) OAI-Providing |
data |
Nein |
Die eigentlichen Daten der Publikation. Oft ein PDF. |
metadata oder metadata2 |
Nein |
Bibliografische Metadaten. Metadata2 wurde mit dem Umstieg auf die Lobid-API v2 eingeführt. |
objectTimestamp |
Nein |
Eine Datei mit einem Zeitstempel. Der Zeitstempel wird bei bestimmten Aktionen gesetzt. |
seq |
Nein |
Eine Hilfsdatei mit einem JSON-Array. Das Array zeigt an, in welcher Reihenfolge Kindobjekte anzuzeigen sind. Dieses Hilfskonstrukt existiert, da in der RELS-EXT keine RDF-Listen abgelegt werden können. |
conf |
Nein |
Websites und Webschnitte speichern in einem conf-Datenstrom alle Parameter mit denen die zugehörige Webseite geharvested wurde. |
Die Metadaten werden als ASCII-Kodierte N-Triple abgelegt. Da alle Fedora-Daten als Dateien im Dateisystem abgelegt werden, ist diese Veriante besonders robust gegen Speicherfehler. N-Triple ist ein Format, dass sich Zeilenweise lesen lässt. ASCII ist die einfachste Form der Textkodierung.
Die Daten werden als "managed"-Datastream in den Objektspeicher der Fedora abgelegt. Eine Ausnahme bilden Webseiten. Die als WARC gespeicherten Inhalte werden "unmanaged" lediglich verlinkt. Im Fedora Objektspeicher wird nur eine Datei mit der ensprechenden Referenz abgelegt.
2.2. Namespaces und Identifier
Jede Regal-Installation arbeitet auf einem festgelegten Namespace. Wenn über die regal-api Objekte angelegt werden, finden sich diese immer in dem entsprechenden Namespace wieder. Hinter dem Namespace findet sich, abgetrennt mit einem Dopplepunkt eine hochlaufende Zahl, die i.d.R. über Fedora Commons 3 bezogen wird.
Der so zusammengesetzte Identifier kommt in allen Systemkomponenten zum Einsatz.
| ID | Komponente | URL |
|---|---|---|
regal:1 |
drupal |
|
regal:1 |
regal-api |
|
regal:1 |
fedora |
|
regal:1 |
elasticsearch |
2.3. Deskriptive Metadaten
Regal unterstützt eine große Anzahl von Metadatenfeldern zur Beschreibung von bibliografischen Ressourcen. Jedes in Regal verspeicherte Objekt kann mit Hilfe von RDF-Metadaten beschrieben werden. Das System verspeichert grundsätzlich alle Metadaten, solange Sie im richtigen Format an die Schnittstelle gespielt werden.
Darüberhinaus können über bestimmte Angaben, bestimmte weitergehende Funktionen angesteuert werden. Dies betrifft u.A.:
-
Anzeige und Darstellung
-
Metadatenkonvertierungen
-
OAI-Providing
-
Suche
Alle bekannten Metadateneinträge werden in der Komponente Etikett verwaltet. In Etikett kann konfiguriert werden, welche URIs aus den RDF-Daten in das JSON-LD-Format von regal-api überführt werden. Außerdem kann die Reihenfolge der Darstellung, und das Label zur Anzeige gesetzt werden.
| Label | Pictogram | Name (json) | URI | Type | Container | Comment |
|---|---|---|---|---|---|---|
Titel |
keine Angabe |
title |
String |
keine Angabe |
keine Angabe |
"title":{
"@id"="http://purl.org/dc/terms/title",
"label"="Titel"
}
Die etikett Datenbank wird beim Neustart jeder regal-api-Instanz eingelesen. Außerdem wird die HTTP-Schnittstelle von Etikett immer wieder angesprochen um zur Anzeige geeignete Labels für URIs in das System zu holen. Das regal-api-Modul läuft dabei auch ohne den Etikett-Services, allerdings nur mit eingeschränkter Funktionalität; beispielsweise fallen Anzeigen von verlinkten Ressourcen (und das ist in Regal fast alles) weniger schön aus.
2.3.1. Wie kommen bibliografische Metadaten ins System?
In Regal können bibliografische Metadaten aus dem hbz-Verbundkatalog an Ressourcen "angelinkt" werden. Dies erfolgt über Angabe der ID des entsprechenden Titelsatzes (z.b. HT017766754). Mit Hilfe dieser ID kann Regal einen Titelimport durchführen. Dabei wird auf die Schnittstellen der Lobid-API zugegriffen.
Regal bietet außerdem die Möglichkeit Metadaten über Erfassungsmasken zu erzeugen und zu speichern. Dies erfolgt mit Hilfe des Moduls Zettel. Zettel ist ein Webservices, der verschiedene HTML-Formulare bereitstellt. Die Formulare können RDF-Metadaten einlesen und ausgeben. Zettel-Formulare werden über Javascript mit Hilfe eines IFrame in die eigentliche Anwendung angebunden. Über Zettel werden Konzepte aus dem Bereich Linked Data umgesetzt. So können Feldinhalte über entsprechende Eingabeelemente in Drittsystemen recherchiert und verlinkt werden. Die Darstellung von Links erfolgt in Zettel mit Hilfe von Etikett. Umfangreichere Notationssysteme wie Agrovoc oder DDC werden über einen eigenen Index aus dem Modul skos-lookup eingebunden. Zettel unterstützt zur Zeit folgende Linked-Data-Quellen:
-
Lobid (GND)
-
Lobid (Ressource)
-
Agrovoc
-
DDC
-
CrossRef (Funder Registry)
-
Orcid
-
Geonames
-
Open Street Maps Koordinaten
2.4. Anzeige und Darstellung
Über die Schnittstellen der regal-api können unterschiedliche Darstellungen einer Publikation bezogen werden. Über Content Negotiation können Darstellungen per HTTP-Header angefragt werden. Um unterschiedliche Darstellungen im Browser anzeigen zu lassen, kann außerden, über das Setzen von entsprechenden Endungen, auf unterschiedliche Representationen eine Resource zugegriffen werden.
/resource/danrw:1 /resource/danrw:1.json /resource/danrw:1.rdf /resource/danrw:1.epicur /resource/danrw:1.mets
In der HTML-Darstellung greift regal-api auf den Hilfsdienst Thumby zu, um darüber Thumbnail-Darstellungen von PDFs oder Bilder zu kreieren. Bei großen Bildern wird außerdem der Deepzoomer angelinkt, der eine Darstellung von Hochauflösenden Bildern über das Tool OpenSeadragon erlaubt. Video- und Audio-Dateien werden über die entsprechenden HTML5 Elemente gerendert.
2.5. Der hbz-Verbundkatalog
Metadaten, die über den Verbundkatalog importiert wurden, können über einen Cronjob regelmäßig aktualisiert werden. Außerdem können diese Daten über OAI-PMH an den Verbundkatalog zurückgeliefert werden, so dass dieser, Links auf die Volltexte erhält.
2.6. Metadatenkonvertierung
Für die Metadatenkonvertierung gibt es kein festes Vorgehensmodell oder Werkzeug. I.d.R. gibt es für jede Representation eine oder eine Reihe von Javaklassen, die für eine On-the-fly-Konvertierung sorgen. Die HTML-Darstellung basiert grundlegend auf denselben Daten, die auch im Elasticsearch-Index liegen und ist im wesentlichen eine JSON-LD-Darstellung, die mit Hilfe der in Etikett hinterlegten Konfiguration aus den bibliografischen Metadaten gewonnen wurde.
2.7. OAI-Providing
Öffentlich zugängliche Publikationen sind auch über die OAI-Schnittstelle verfügbar. Dabei wird jede Publikation einer Reihe von OAI-Sets zugeordnet und in unterschiedlichen Formaten angeboten.
| Set | Kriterium |
|---|---|
ddc:* |
Wenn ein dc:subject mit dem String "http://dewey.info/class/" beginnt, wird ein Set mit der entsprechenden DDC-Nummer gebildet und die Publikation wird zugeordnet |
contentType |
Der "contentType" weist darauf hin, in welcher Weise die Publikation in Regal. Abgelegt ist. |
open_access |
All Publikationen, die als Sichtbarkeit "public" haben |
urn-set-1 |
Publikationen mit einer URN, die mit urn:nbn:de:hbz:929:01 beginnt |
urn-set-2 |
Publikationen mit einer URN, die mit urn:nbn:de:hbz:929:02 beginnt |
epicur |
Publikationen, die in einem URN-Set sind |
aleph |
Publikationen , die mit einer Aleph-Id verknüpft sind |
edoweb01 |
spezielles, pro regal-api-Instanz konfigurierbares Set für alle Publikationen, die im aleph-Set sind |
ellinet01 |
spezielles, pro regal-api-Instanz konfigurierbares Set für alle Publikationen, die im aleph-Set sind |
| Format | Kriterium |
|---|---|
oai_dc |
Alle öffentlich sichtbaren Objekte, die als bestimmte ContentTypes angelegt wurden. |
epicur |
Alle Objekte, die eine URN haben |
aleph |
Alle Objekte, die einen persistenten Identifier haben |
mets |
Wie oai_dc |
rdf |
Wie oai_dc |
wgl |
Format für LeibnizOpne. Alle Objekte die über das Feld "collectionOne" einer Institution zugeordnet wurden und über den ContentType "article" eingeliefert urden. |
2.8. Suche
Der Elasticsearch-Index wird mit Hilfe einer JSON-LD Konvertierung befüllt. Die Konvertierung basiert im wesentlichen auf den bibliografischen Metadaten der einzelnen Ressourcen und wir mit Hilfe der in Etikett hinterlegten Konfiguration erzeugt.
2.9. Zugriffsberechtigungen und Sichtbarkeiten
Regal setzt ein rollenbasiertes Konzept zur Steuerung von Zugriffsberechtigungen um. Eine besondere Bedeutung kommt dem lesenden Zugriff auf Ressourcen zu. Einzelne Ressourcen können in ihrer Sichtbarkeit so eingeschränkt werden, dass nur mit den Rechten einer bestimmten Rolle lesend zugegriffen werden kann. Dabei kann der Zugriff auf Metadaten und Daten separat gesteuert werden.
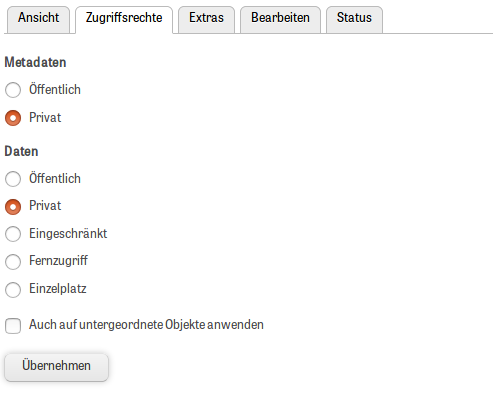
Die Konfiguration hat Auswirkungen auf die Sichtbarkeit einer Publikation in den unterschiedlichen Systemteilen. Die folgende Tabelle veranschaulicht den derzeitigen Stand der Implementierung.
2.9.1. Sichtbarkeiten, Operationen, Rollen
Rolle |
Art der Aktion |
ADMIN |
Darf alle Aktionen durchführen. Auch Bulk-Aktionen und "Purges" |
EDITOR |
Darf Objekte anlegen, löschen, Sichtbarkeiten ändern, etc. |
| Sichtbarkeit | Rolle |
|---|---|
public |
GUEST,READER,SUBSCRIBER,REMOTE,ADMIN,EDITOR |
private |
ADMIN,EDITOR |
| Sichtbarkeit | Rolle |
|---|---|
public |
GUEST,READER,SUBSCRIBER,REMOTE,ADMIN,EDITOR |
restricted |
READER,SUBSCRIBER,REMOTE,ADMIN,EDITOR |
remote |
READER,SUBSCRIBER,REMOTE,ADMIN,EDITOR |
single |
SUBSCRIBER,ADMIN,EDITOR |
private |
ADMIN,EDITOR |
2.10. Benutzerverwaltung
Die Benutzerverwaltung von Regal findet innerhalb von Drupal statt. Zwar können auch in der regal-api Benutzer angelegt werden, jedoch ist die Implementierung in diesem Bereich erst rudimentär.
2.10.1. Drupal
Benutzer in Drupal können über das Modul regal-drupal unterschiedliche Rollen zugewiesen werden. Die Authorisierung erfolgt passwortbasiert. Alle Drupal-Benutzer greifen über einen vorkonfigurierten Accessor auf die regal-api zu. Alle Zugriffe erfolgen verschlüsselt unter Angabe eines Passwortes. Die Rolle mit deren Berechtigungen zugegriffen wird, wird dabei in regal-drupal gesetzt. Die Drupal-BenutzerId wird als Metadatum in Form eines proprietären HTTP-Headers mit an regal-api geliefert.
2.10.2. Regal-Api
Auch in regal-api können Api-Benutzer angelegt werden. Zur Benutzerverwaltung wird eine MySQL-Datenbank eingesetzt, in der die Passworte der Nutzer abgelegt sind (Hash+Salt).
2.11. Ansichten
Um Daten, die in regal-api abgelegt wurden zur Anzeige zu bringen sind i.d.R. mehrere Schritte nötig. Die genaue Vorgehensweise ist davon abhängig, wo die Daten abgelegt werden (in welchem Fedora Datenstrom). Grundsätzlich basiert die HTML-Darstellung auf den Daten, die unter dem Format .json2 einer Ressource abrufbar sind und einen Eintrag in context.json haben.
Daten zur Ansicht bringen
-
Eintrag des zugehörigen RDF-Properties in die entsprechende Etikett-Instanz, bzw. in die
/conf/labels.json. Der Eintrag muss einen Namen, ein Label und einen Datentyp haben. regal-api neu starten, bzw mitPOST /context.jsondas neu Laden der Contexteinträge erzwingen. -
Dies müsste reichen, um eine Standardanzeige in der HTML-Ausgabe zu erreichen
-
Wenn die Daten nicht erscheinen, sollte man überprüfen, ob sie unter dem Format
.json2erscheinen. Wenn nicht, stellt sich die Frage, wo die Daten abgelegt werden. Komplett werden nur die Daten aus dem Fedora Datenstrom /metadata2 prozessiert. Befindet sich das Datum in z.B. im /RELS-EXT Datenstrom so muss es zunächst manuell unterhelper.JsonMapper#getLd2()in das JSON-Objekt eingefügt werden. -
Einige Felder werden auch ausgeblendet. Dies geschieht in regal-api unter
/public/stylesheets/main.cssund in Drupal innerhalb der entsprechenden themes. -
Um spezielle Anzeigen zu realisieren muss schließlich im HTML-Template angefasst werden, unter
/app/views/tags/resourceView.scala.html.
Insgesamt läuft es also so: Alles was in Etikett konfiguriert ist, wird auch ins JSON und damit ins HTML übernommen. Dinge, die im HTML nicht benötigt werden, werden über CSS wieder ausgeblendet.
3. Software
Die technische Dokumentation der HTTP-Schnittstelle findet sich unter API Doku
Nachfolgend sei eine Innenansicht der einzelnen Module aufgestellt. Die Integration der Module erfolgt i.d.R. über HTTP. Die Module werden über entsprechende Einträge in der Apache-Konfiguration sichtbar gemacht. Es handelt sich also um eine Webservice-Architektur, in der alle Webservices über einen Apache-Webserver und entsprechende Einträge in ihren Konfigurationsdateien miteinander verbunden werden.
3.1. regal-api
Source |
|
Technik |
|
Ports |
9000 / 9100 |
Verzeichnis |
/opt/regal/apps/regal , /opr/regal/src/regal |
HTTP Pfad |
/ |
Mit regal-api werden alle grundlegenden Funktionen von Regal bereitgestellt. Dies umfasst:
-
HTTP Schnittstelle
-
Sichtbarkeiten, Zugriffskontrolle, Rollen
-
Speicherung, Datenhaltung
-
Konvertierungen
-
Ansichten
-
Suche
-
Webarchivierung
Der Webservice ist auf Basis von Play 2.4.2 realisiert und bietet eine reichhaltig HTTP-API zur Verwaltung von elektronischen Publikationen an. Die regal-api operiert auf Fedora Commons 3, MySql und Elasticsearch 1.1. Über die API werden auch Funktionalitäten von Etikett, Thumby, Zettel und Deepzoomer angesprochen. Für die Webarchivierung werden heritrix, wpull und openwayback angebunden.
3.1.1. Konfiguration
| Datei | Beschreibung |
|---|---|
aggregations.conf |
Diese Datei wird verwendet um die Schnittstelle |
application.conf.tmpl |
Eine template Datei für die Hauptkonfiguration von regal-api. Diese Datei sollte zur lokalen Verwendung einmal nach application.conf kopiert werden. In der Datei sind alle Passwörter auf admin gesetzt. |
crawler-beans.cxml |
Die Datei wird verwendet, wenn im Webarchivierungsmodul eine neue Konfiguration für eine Webseite angelegt wird. |
ehcache.xml |
die Konfiguration der Ehcache Komponente |
fedora-users.xml |
deprecated - Zur Löschung vorgeschlagen |
hbz_edoweb_url.txt |
deprecated - Zur Löschung vorgeschlagen |
html.html |
deprecated - Zur Löschung vorgeschlagen |
install.properties |
deprecated - Zur Löschung vorgeschlagen |
labels-edoweb.de |
Labels für eine bestimmt Regal-Instanz |
labels-for-proceeding-and-researchData.json |
deprecated - Zur Löschung vorgeschlagen |
labels-lobid.json |
deprecated - Zur Löschung vorgeschlagen |
labels-publisso.de |
Labels für eine bestimmte Regal-Instanz |
labels.json |
Eine sinnvolle Startkonfiguration. Die Datei wurde mit Etikett erzeugt. Beim Start von regal-api wird zunächst versucht eine ähnliche Konfiguration direkt von einer laufenden Etikett-Instanz zu holen. Wenn dies nicht klappt, wird auf die labels.json zurückgegriffen. |
list.html |
deprecated - Zur Löschung vorgeschlagen |
logback.developer.xml |
ein logging Konfiguration. Ich kopiere die immer nach logback.developer.js.xml (in .gitignore) und trage sie dann in die application.conf ein. Auf diese Weise kann ich an Loglevels herumkonfigurieren ohne das in diese Änderungen in die Versionsverwaltung spielen zu müssen. |
logback.xml |
Konfiguration des Loggers. Diese Datei ist in application.conf eingetragen. |
mabxml-string-template-on-record.xml |
Eine template-Datei zur Generierung von MAB-Ausgaben. |
mail.properties |
Konfiguration zur Versendung von Mails. Standardmäßig schickt die Applikation eine Mail, sobald sie im Production-Mode neu gestartet wurde. Auch der Umzugsservice im Webarchivierungsmodul verschickt Mails. |
nwbib-spatial.ttl |
deprecated - Zur Löschung vorgeschlagen |
nwbib.ttl |
deprecated - Zur Löschung vorgeschlagen |
public-index-config.json |
Konfiguration des Elasticsearch-Indexes. Da in dem Index vorallem Metadaten liegen, soll fast nicht tokenisiert werden. |
routes |
Hier sind alle HTTP-Pfade übersichtlich aufgeführt. |
scm-info.sh |
Diese Datei kann man unter Linux in die profile-Konfiguration seines Benutzers einbinden. Dann erhält man im Terminal farbige Angabgen zu Git-Branches,etc. |
start-regal.sh |
deprecated - Zur Löschung vorgeschlagen |
tomcat-users.xml |
deprecated - Zur Löschung vorgeschlagen |
unescothes.ttl |
deprecated - Zur Löschung vorgeschlagen |
wglcontributor.csv |
deprecated - Zur Löschung vorgeschlagen |
3.1.2. Die Applikation
| Package | Beschreibung |
|---|---|
default package |
Hier befindet sich die Datei Global, die in Play 2.4 noch eine große Rolle spielt. In der Datei können zum Beispiel Aktionen vor dem Start der Applikation erfolgen, auch können hier HTTP-Requests mit geloggt werden. Bestimmte Aktionen werden nur im Production-Mode ausgeführt, d.h. nur wenn die Applikation mit |
actions |
Hier sind Funktionen versammelt, die meist unmittelbar aus den Controller-Klassen aufgerufen werden. |
archive.fedora |
Ein Reihe von Dateien, über die Zugriffe auf Fedora Commons 3 organisiert werden. Hier finden sich auch einige Hilfsklassen ( |
archive.search |
Zugriff auf die Elasticsearch |
authenticate |
Regal verwendet Basic-Auth zur Authentifizierung. Um die entsprechenden Aufrufe in den Controllern zu Schützen wird eine Annotation |
controllers |
Der Code, der in diesen Klassen organisiert ist, wird bei den entsprechenden HTTP-Aufrufen ausgeführt. In der |
converter.mab |
Diese Datei realisiert das OAI-Providing von MAB-Daten. Ursprünglich war geplant, wesentlich umfangreichere MAB-Datensätze an den Verbundkatalog zu liefern. Daher wird hier mit einer eigenen Template-Engine gearbeitet, etc. Ein lustiges Produkt in diesem Kontext ist auch die Klasse |
de.hbz.lobid.helper |
Der hier befindliche Code kommt ursprünglich aus einem anderen Paket, wurde dann aber beim Neuaufbau des Lobid 2 Datendienstes gemeinsam mit den Kollegen weiterentwickelt und ist schließlich wieder hier gelandet. Mittlerweile ist die offizielle JSON-LD-Library soweit entwickelt, dass man die Konvertierung auch darüber machen kann. Achja, denn dafür ist der Code: Lobid N-Triples in schönes JSON umzuformen, das dann auch in den Elasticsearch-Index kann. |
helper |
Die mit Abstand wichtigste Klasse in diesem Package heißt |
helper.mail |
Emails verschicken. |
helper.oai |
Einige Klassen zur Regelung des OAI-Providings. Der |
models |
Die wichtigste Klasse hier ist |
views |
Templates in der Sprache |
views.mediaViewers |
Ein paar Viewer, die über die Hilfsklasse |
views.oai |
Mit |
views.tags |
Hilfstemplates. |
3.2. Etikett
Source |
|
Technik |
|
Ports |
9002 / 9102 |
Verzeichnis |
/opt/regal/apps/etikett , /opr/regal/src/etikett |
HTTP Pfad |
/tools/etikett |
Etikett ist eine einfache Datenbankanwendung, die es erlaubt
-
Menschenlesbare Labels für URIs abzulegen. Über eine HTTP-Schnittstelle kann dann nach dem Label gefragt werden.
-
Auch Konfigurationen zur Erzeugung eines JSON-LD Kontextes können abgelegt werden.
-
Die Etikett-Datenbank erweitert sich dynamisch. Wird in einem authentifizierten Zugriff nach einer noch nicht bekannten URI gefragt, so versucht die Applikation ein Label für die URI zu finden.
In Etikett sind verschiedene Lookups realisiert, die dynamisch Labels für URIs finden können. Beispiele:
-
Crossref
-
Geonames
-
GND
-
Openstreetmap
-
Orcid
-
RDF, Skos, etc.
Fragt man Etikett nach einem Label, so antwortet Etikett mit dem Ergebnis des Lookups. Wenn Etikett nicht in der Lage ist, ein Label zu finden, wird die URI, mit angefragt wurde, zurückgegeben.
Etikett kann auch als Cache verwendet werden. So werden authentifizierte Anfragen in einer Datenbank persistiert. Erneute Anfragen werden dann aus der Datenbank beantwortet, ein erneuter Lookup wird eingespart. Einmal persistierte Labels werden nicht invalidiert. Die Invalidierung kann von außerhalb über authentifizierte HTTP-Zugriffe realisiert werden, stellt aber insgesamt noch ein Desiderat dar.
Etikett kann auch mit Labels vorkonfiguriert werden. Dabei können zusätzliche Informationen zu jeder URIs mit abgelegt werden. Folgende Informationen können in etikett abgelegt werden:
-
URI
-
Label
-
Weight - Zur Definition von Anzeigereihenfolgen.
-
Pictogram Iconfont-ID - Kann anstatt oder zusätzlich zum Label angezeigt werden.
-
ReferenceType - JSON-LD Typ
-
Container - JSON-LD Container
-
Beschreibung - Kommentar als Markdown
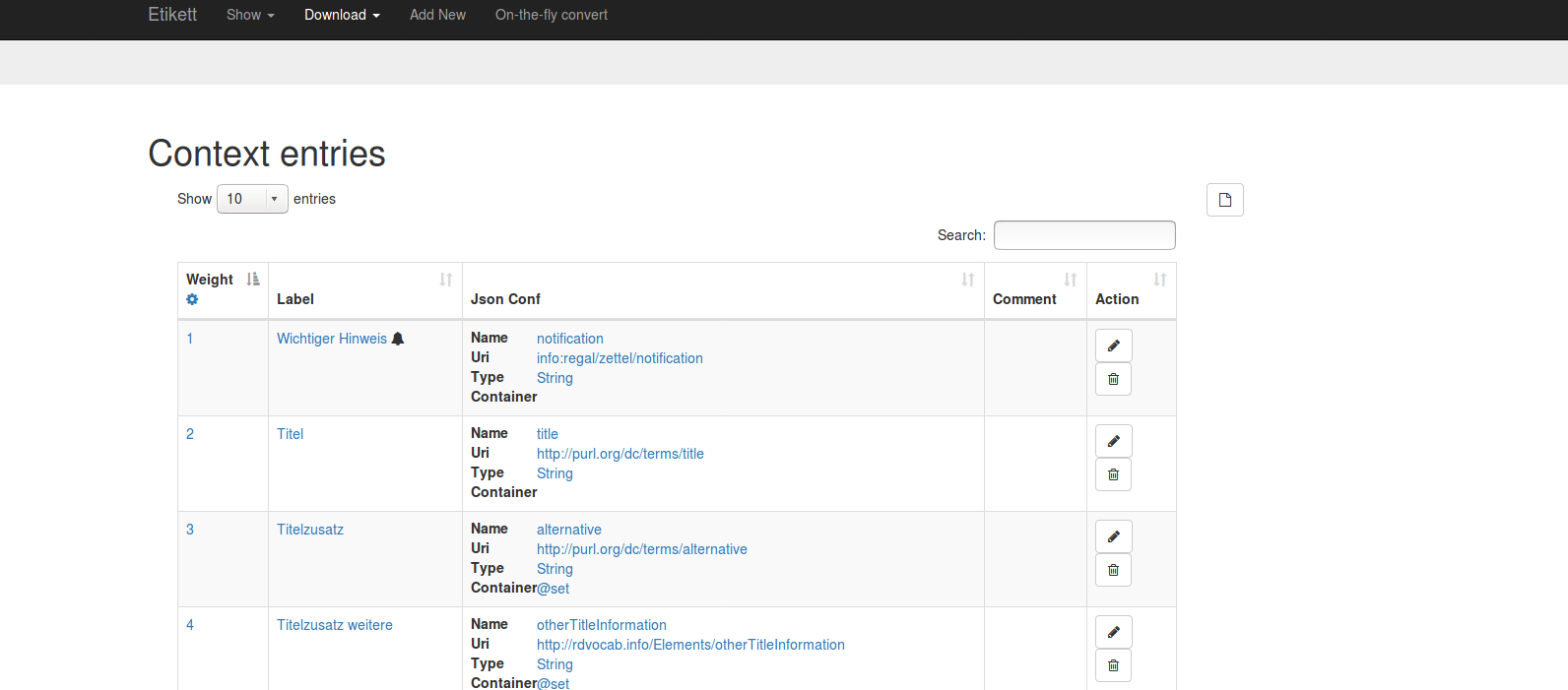
Mit Hilfe dieser Angaben kann Etikett auch einen "JSON-LD Context" bereitstellen. Insgesamt wird über Etikett eine Art "Application Profile" realisiert. Das Profil gibt Auskunft, welche Metadatenfelder (definiert als URIs) in welcher Weise (Typ, Container) Verwendung finden und wie sie angezeigt werden sollen (Label, Weight, Pictogram).
Im Regal-Kontext wird Etikett an vielen Stellen verwendet.
-
Zur Wandlung von RDF nach JSON-LD
-
Zur Anreicherung von RDF Importen
-
Zur menschenlesbaren Darstellung von RDF
-
Zur Konfiguration von Labels, Anzeigereihenfolgen und Pictogrammen
-
Als Cache
3.2.1. Konfiguration
| Datei | Beschreibung |
|---|---|
evolutions |
Dieses Verzeichnis enthält SQL-Skripte, die bei Änderungen des Datenbankschemas automatisch über EBean angelegt werden. Beim nächsten Deployment einer neuen Etikett-Version werden die Skripte automatische angewendet. Die Skripte enthalten immer einen mit "Up" markierten Part, und einen mit "Down" markierten Part (für rollbacks). |
application.conf |
Hier kann ein Benutzer eingestellt werden. Alle Klassen im Verzeichnis |
ddc.turtle |
Eine DDC Datei. Die Datei bietet Labels für DDC-URIs an. |
labels.json |
Eine Labels-Datei, die zur initialen Befüllung verwendet werden kann. |
regal.turtle |
Eine Labels-Datei, die zur initialen Befüllung verwendet werden kann. |
routes |
Alle HTTP-Schnittstellen übersichtlich in einer Datei |
rpb.turtle |
Eine Labels-Datei, die zur initialen Befüllung verwendet werden kann. |
rpb2.turtle |
Eine Labels-Datei, die zur initialen Befüllung verwendet werden kann. |
3.2.2. Die Applikation
| Package | Beschreibung |
|---|---|
default |
In |
controllers |
In |
helper |
Verschiedene Klassen, die eine URI verfolgen und versuchen ein Label aus den zurückgelieferten Daten zu kreieren. |
models |
Das Model |
views |
Die meisten HTTP-Operationen lassen sich auch über eine Weboberfläche im Browser aufrufen. |
3.3. Zettel
Source |
|
Technik |
|
Ports |
9003 / 9103 |
Verzeichnis |
/opt/regal/apps/zettel, /opr/regal/src/zettel |
HTTP Pfad |
/tools/zettel |
Zettel ist ein Webservice zur Bereitstellung von Webformularen. Die Webformulare können über ein HTTP-GET geladen werden. Sollen existierende Daten in ein Formular geladen werden, so können diese Daten (1) als Form-encoded, (2) als JSON, oder (3) als RDF-XML über ein HTTP POST in das Formular geladen werden. Gleichzeitig kann spezifiziert werden, in welchem Format das Formular Daten zurückliefern soll.
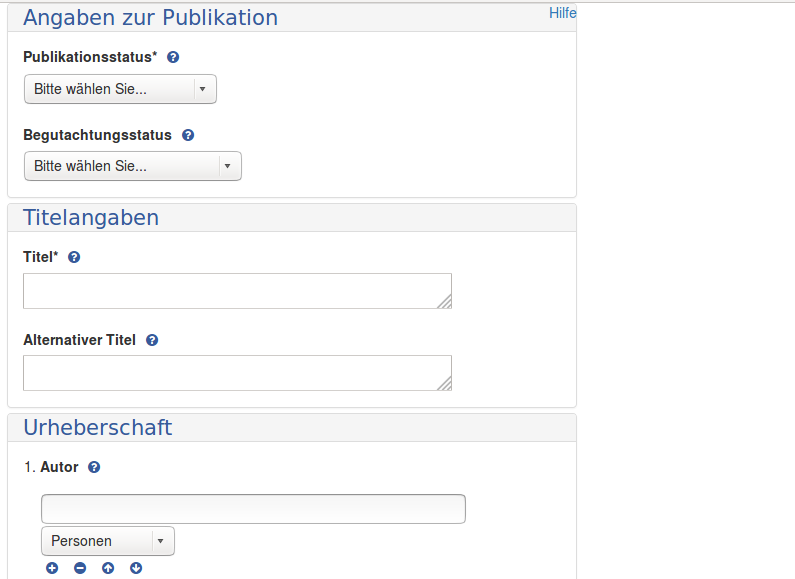
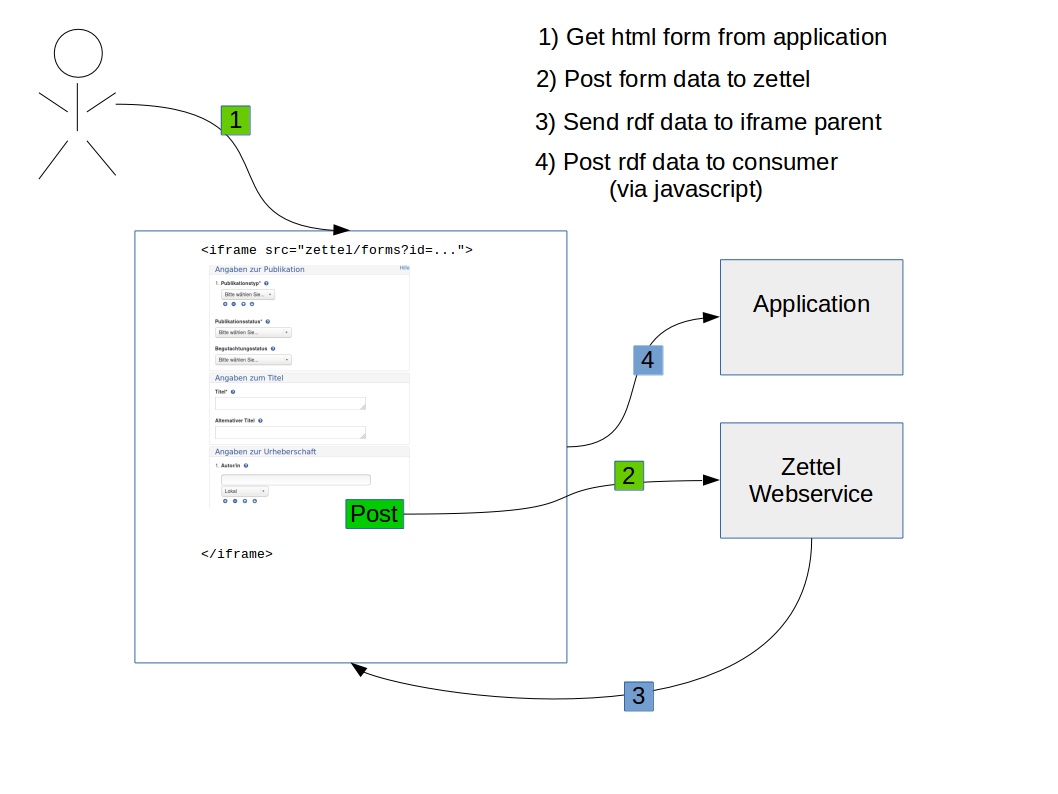
Zettel verfügt über keine eigene Speicherschicht. Daten die über ein Formular erzeugt wurden, werden in der HTTP-Response zurückgeliefert. Zur Integration von Zettel in andere Applikationen wurde ein Kommunikationspattern entwickelt, das auf Javascript beruht. Das Zettel-Formular wird hierzu in einem IFrame in die Applikation eingebunden. Die Applikation muss außerdem ein Javascript einbinden, das auf bestimmte Nachrichten aus dem IFrame lauscht. Bei bestimmte Aktionen sendet das Zettel-Formular dann Nachrichten an die Applikation und erlaubt dieser darauf zu reagieren. Um Daten von Zettel in die Applikation zu bekommen, werden diese im HTML-DOM gespeichert und können von dort durch die Applikation entgegengenommen werden.
3.3.1. Konfiguration
| Datei | Beschreibung |
|---|---|
application.conf |
Die Datei enthält einen Eintrag zur Konfiguration von Etikett. Über einen weiteren Eintrag können "Hilfetexte" angelinkt werden. Die Hilfetexte müssen in einer statischen HTML abgelegt sein. Am Ende der Datei werden einige Limits deutlich über den Standard erhöht, damit die großen RDF-Posts auch funktionieren. |
collectionOne.csv |
Die Datei regelt den Inhalt eines Combo-Box widgets mit id collectionOne. |
ddc.csv |
Die Datei regelt den Inhalt eines Combo-Box widgets mit id ddc. |
labels.json |
Ein paar labels, falls keine Instanz von Etikett erreichbar ist. |
logback.xml |
Logger Konfiguration. |
professionalGroup.csv |
Die Datei regelt den Inhalt eines Combo-Box widgets mit id professionalGroup. |
routes |
Alle HTTP-Pfade übersichtlich in einer Datei |
3.3.2. Die Applikation
| Package | Beschreibung |
|---|---|
controllers |
Es gibt nur einen Controller. Hier ist sowohl die Basisfunktionalität implementiert, als auch die Autocompletion-Endpunkte für die unterschiedlichen Widgets. Die Schnittstelle zu Abhandlung von Formulardaten ist recht generisch gehalten. Über eine ID wird das entsprechende Formular aus dem services.ZettelRegister geholt und das zugehörige Formular wird gerendert. Die Formular erhalten dabei unterschiedliche Templates (z.B. |
models |
Das Model "Article" heißt aus historischen Gründen so. Tatsächlich können mittlerweile auch Kongressschriften und Buchkapitel darüber abgebildet werden (vermutlich wird sich der Name nochmal ändern). Das Model "Catalog" dient zum Import von Daten aus dem Aleph-Katalog (über Lobid). Mit ResearchData steht ein prototypisches Model zur Verarbeitung von Daten über Forschungsdaten zur Verfügung. Alle Models basieren auf einem einzigen "fetten" ZettelModel. Das ZettelModel enthält auch Funktionen zur De/Serialisierung in RDF und Json. |
services |
Hier werden verschiedene Hilfsklassen versammelt. Die Klasse ZettelFields enthält ein Mapping zur RDF-Deserialisierung. |
views |
Alle HTML-Sichten und die eigentlichen Formulare. |
3.4. skos-lookup
Source |
|
Technik |
|
Ports |
9004 / 9104 |
Verzeichnis |
/opt/regal/apps/skos-lookup, /opr/regal/src/skos-lookup |
HTTP Pfad |
/tools/skos-lookup |
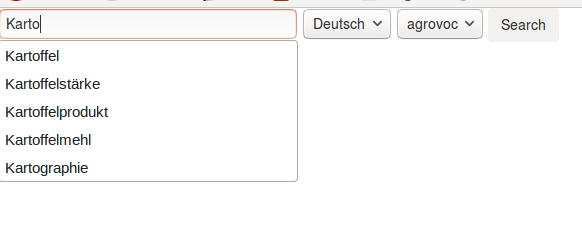
skos-lookup dient zur Unterstützung von Zettel. Der Webservice startet eine eingebettete Elasticsearch-Instanz und verfügt über eine Schnittstelle um SKOS-Daten in separate Indexe zu importieren und Schnittstellen zur Unterstützung von jQuery-Autocomplete- und Select2-Widgets aufzubauen. Auf diese Weise können auch umfangreichere Thesauri und Notationssysteme in den Formularen von Zettel fachgerecht angelinkt werden. skos-lookup unterstützt auch mehrsprachige Thesauri.

3.4.1. Konfiguration
| Datei | Beschreibung |
|---|---|
application.conf |
Hier wird der interne Elasticsearch-Index konfiguriert. Auch werden einige Speichereinstellungen erhöht. Damit auch große SKOS-Dateien geladen werden können, sollten auch die Java-Opts erhöht werden. |
logback.xml |
Logger Konfiguration |
routes |
Alle HTTP-Pfade übersichtlich in einer Datei |
skos-context.json |
Ein JSON-LD-Kontext zur Umwandlung von RDF nach JSON. (Origianl von: Jakob Voss) |
skos-setting.json |
Settings zur Konfiguration des Elasticsearchindexse. (Original von: Jörg Prante) |
3.4.2. Die Applikation
| Package | Beschreibung |
|---|---|
controllers |
Alles in einem Controller. Die API-Methoden liefern HTML und JSON, so dass man sie aus dem Browser, aber auch über andere Tools ansprechen kann. |
elasticsearch |
Eine embedded Elasticsearch. Dies hat den Vorteil, dass man eine aktuellere Version nutzen kann, als z.B. die regal-api. |
services |
Hilfsklassen zum Laden der Daten. |
views |
Ein Formular um neue Daten in die Applikation zu laden. Und ein Beispielformular zur Demonstration der Nutzung. |
3.5. Thumby
Source |
|
Technik |
|
Ports |
9001 / 9101 |
Verzeichnis |
/opt/regal/apps/thumby, /opr/regal/src/thumby |
HTTP Pfad |
/tools/thumby |
Thumby realisiert einen Thumbnail-Generator. Über ein HTTP-GET wird Thumby die URL eines PDFs, oder eines Bildes übergeben. Sofern die Thumby den Server kennt, wird es versuchen ein Thumbnail der zurückgelieferten Daten zu erstellen. Die Daten werden dauerhaft auf der Platte abgelegt und zukünftige Requests, die auf dasselbe Bild verweisen werden direkt aus dem Speicher von Thumby beantwortet.
3.5.1. Konfiguration
| Datei | Beschreibung |
|---|---|
application.conf |
Hier wird eine Whitelist gesetzt. Thumby verarbeitet nur URLs von den hier angegebenen Quellen. Hier wird auch der Pfad auf der Platte gesetzt, unter dem Thumby thumbnail-Daten ablegt. |
routes |
Alle HTTP-Pfade übersichtlich in einer Datei |
3.5.2. Die Applikation
| Package | Beschreibung |
|---|---|
controllers |
Der Controller realisiert eine GET-Methode, über die Thumbnails erzeugt und zurückgegeben werden. |
helper |
Klassen zur Organisation des Speichers und zur Thumbnailgenerierung. |
views |
Es gibt eine Oberfläche mit einem Upload-Formular. |
3.6. Deepzoomer
Source |
|
Technik |
|
Ports |
9091 / 9191 |
Verzeichnis |
/opt/regal/tomcat-for-deepzoom/, /opr/regal/src/DeepZoomService |
Der [DeepZoomService] kann als WAR in einem Application-Server deployed werden. Mit dem Deepzoomer können pyramidale Bilder erzeugt, gespeichert und über eine OpenSeadragon-konforme Schnittstelle abgerufen werden. Auf diese Weise kann in Regal eine Viewer-Komponente realisiert werden, die die Anzeige sehr großer, hochaufgelöster Bilder im Webbrowser unterstützt.
3.6.1. Konfiguration
| Datei | Beschreibung |
|---|---|
deepzoomer.cfgf |
Hier werden lokale Verzeichnisse, aber auch die Server-URLs, unter denen der Service öffentlich abrufbar ist, gesetzt. |
3.7. regal-drupal
Source |
|
Technik |
|
Ports |
80 / 443 |
Verzeichnis |
/opt/regal/var/drupal/sites/all/modules/ |
Ein Drupal 7 Modul über das Funktionalitäten der regal-api angesprochen werden können. Das Modul bietet Oberflächen zur Konfiguration, zur Suche und zur Verwaltung von Objekthierarchien.
3.7.1. Die Applikation
| Verzeichnis | Beschreibung |
|---|---|
edoweb |
Hier ist der Code für die Oberflächen. |
edoweb-field |
Hier werden Felder für unterschiedliche RDF-Properties in der Drupal-Datenbank konfiguriert. Der Code ist größtenteils obsolet, da die Feldlogik nicht mehr benutzt wird. |
edoweb_storage |
Hier sind die Zugriffe auf regal-api und [_elasticsearch] zu finden. |
3.8. edoweb-drupal-theme
Source |
|
Technik |
|
Ports |
80 / 443 |
Verzeichnis |
/opt/regal/var/drupal/sites/all/themes/ |
Eine Reihe von Stylsheets, CSS, Icons zur Gestaltung einer Oberfläche für den Server https://edoweb-rlp.de
3.9. zbmed-drupal-theme
Source |
|
Technik |
|
Ports |
80 / 443 |
Verzeichnis |
/opt/regal/var/drupal/sites/all/themes/ |
Eine Reihe von Stylsheets, CSS, Icons zur Gestaltung einer Oberfläche für den Server https://repository.publisso.de
3.10. openwayback
Repo: https://github.com/iipc/openwayback Servlet 2.5 .Überblick
Source |
|
Technik |
|
Ports |
8091 / 8191 |
Verzeichnis |
/opt/regal/tomcat-for-openwayback/, /opr/regal/src/openwayback |
Achtung: Es gibt einen am hbz entwickelten Branch. Dieser ist nicht auf Github.
Openwayback ist eine Webapplikation die im ROOT Bereich eines Tomcats installiert werden will. Sie kann Verzeichnisse mit WARC-Dateien indexieren und darauf eine Oberfläche zur Recherche und zur Navigation aufbauen.
3.11. heritrix
Heritrix ist ein Werkzeug zur Sammlung von Webseiten. Heritrix startet standalone als Webapplikation und bietet eine Weboberfläche zur Verwaltung von Sammelvorgängen an. Eingesammelte Webseiten werden als WARC-Dateien in einem bestimmten Bereich der Platte abgelegt.
3.12. wpull
Wpull ist ein Kommandozeilen-Wermzeug zur Sammlung von Webseiten. Mit WPull können WARC-Dateien erzeugt werden.
3.13. Fedora Commons 3
Fedora Commons 3 ist ein Repository-Framework. Für Regal wird vorallem die Speicherschicht von Fedora Commons 3 benutzt. Fedora-Commons legt alle Daten im Dateisystem (auch) ab. Mit den Daten aus dem Dateisystem lässt sich eine komplette Fedora-Commons 3 Instanz von grundauf neu aufbauen.
3.14. MySql
MySQL wir von Fedora, regal-api und etikett verwendet.
3.15. Elasticsearch 1.1
Elasticsearch ist eine Suchmaschine und wird von regal-api verwendet. Auch regal-drupal greift auf den Index zu.
3.16. Drupal 7
Über Drupal 7
4. Installation
4.1. Vagrant
Zur Veranschaulichung dieser Dokumentation wird ein Vagrant-Skript angeboten, mit dem eine Regal-Installation innerhalb eines VirtualBox-Images erzeugt werden kann.
Zur Installation kannst Du folgende Schritte ausführen. Die Kommandos beziehen sich auf die Installation auf einem Ubuntu-System. Für andere Betriebssyteme ist die Installation ähnlich.
Die VirtualBox hat folgendes Setup
-
hdd 40GB
-
cpu 2core
-
ram 4096G
4.1.1. VirtualBox installieren
sudo apt-get install virtualbox
4.1.2. Vagrant installieren
cd /tmp wget https://releases.hashicorp.com/vagrant/2.2.3/vagrant_2.2.3_x86_64.deb sudo dpkg -i vagrant_2.2.3_x86_64.deb
4.1.3. Repository herunterladen
git clone https://github.com/jschnasse/Regal cd Regal/vagrant/ubuntu-14.04
4.1.4. Eine JDK8 bereitstellen
Hierfür bitte ein JDK8-Tarball herunterladen und unter dem Namen java8.tar.gz in einem Verzeichnis /bin unterhalb des Vagrant-Directories bereitstellen.
mkdir bin mv ~/downloads/jdk.... bin/java8.tar.gz
4.1.5. Geteiltes Entwicklungsverzeichnis
mkdir ~/regal-dev
4.1.6. Vagrant Guest Additions installieren
vagrant plugin install vagrant-vbguest && vagrant reload
4.1.7. Vagrant Host anlegen
Damit alle Dienste komfortabel erreichbar sind, muss in die lokale HOSTs Datei ein Eintrag für die Vagrant-Box erfolgen. Im Vagrantfile ist die IP 192.168.50.4 für die Box konfiguriert. Über die FRONTEND und BACKEND Einträge in der variables.conf ist der Servername als regal.vagrant definiert.
sudo printf "192.168.50.4 regal.vagrant api.regal.vagrant" >> /etc/hosts
4.1.8. Vagrant starten
vagrant up
4.1.9. Auf der Maschine einloggen
vagrant ssh
4.2. Server
Die Installation auf einem Server kann mit Hilfe des mitgelieferten Skriptes regal-install.sh erfolgen. Dazu muss analog zur Vagrant-Installation zunächst das bin Verzeichnis mit einem JDK aufgebaut werden. Danach erfolgt die Installation unter /opt/regal und mit einem Benutzer regal (vgl. variables.conf)
4.2.1. Hardware Empfehlung
-
hdd >500GB
-
cpu 8 core
-
ram 32 G
4.2.2. Unterschiede zur Vagrant Installation
Auf dem Server empfehlen ich den fedora tomcat mit erweiterten Speichereinstellungen zu betreiben.
Dazu in /opt/regal/bin/fedora/tomcat/bin eine setenv.sh anlegen und folgende Zeilen hinein kopieren.
CATALINA_OPTS=" \ -Xms1536m \ -Xmx1536m \ -XX:NewSize=256m \ -XX:MaxNewSize=256m \ -XX:PermSize=256m \ -XX:MaxPermSize=256m \ -server \ -Djava.awt.headless=true \ -Dorg.apache.jasper.runtime.BodyContentImpl.LIMIT_BUFFER=true" export CATALINA_OPTS
5. Entwicklung Java
5.1. In der VirtualBox
Hat man über Vagrant eine neue VirtualBox erzeugt und alle Konfigurationen wie beschrieben vorgenommen, kann man die VirtualBox zur Entwicklung nutzen. Da im Installationsprozess bereits Eclipse-Projekte der unter /opt/regal/src befindlichen Java-Applikationen erzeugt wurden, können die Projekte direkt aus dem "synced folder" unter ~/regal-dev in eine Eclipse-IDE auf dem Host-System importiert werden.
Damit Änderungen am Code in der VirtualBox direkt sichtbar werden, sollte die Applikation zunächst im Develop-Mode neu gestartet werden. Dazu loggt man sich auf der VirtualBox mit vagrant ssh ein und stoppt zunächst den entsprechenden Service, z.B. sudo service regal-api stop. Anschließend navigiert man in das Source-Verzeichnis, z.B. cd /opt/regal/src/regal-api. Hier startet man die Applikation auf dem korrekten Port (im Zweifel unter /opt/regal/apps/regal-api/conf/application.conf nachschauen). Der Start im Develop-Mode erfolgt aus dem Verzeichnis der Applikation, mit z.B. /opt/regal/bin/activator/bin/activator -Dhttp.port=9100. Danach kann in die Kosole run eingegegeben werden. Die Applikation sollte nun unter dem entsprechenden Port (im Beispiel: 9100) antworten.
5.2. Auf dem eigenen System
Die Javakomponenten können problemlos auch auf einem aktuellen Ubuntusystem entwickelt werden. Leider läuft die PHP/Drupal-Implementierung nicht unter neueren Ubuntusystemen. Für die lokale installation können die entsprechenden Funktionen aus dem regal-install.sh ausgeführt werden. Dazu einfach eine Kopie anlegen, entsprechend editieren und ausführen.
mkdir regal-install cp -r path/to/Regal/vagrant/ubuntu-XX/* regal-install cd regal-install # Edit system user "vagrant" --> "your user" editor variables.conf # put drupal stuff in comments # # #installDrush # #installDrupal # #installRegalDrupal # #installDrupalThemes # #configureDrupalLanguages # #configureDrupal # editor regal-install.sh
6. Administration
6.1. Aktualisierung
6.1.1. Play-Applikationen
Die Aktualisierung der Regal-Komponenten erfolgt über Skripte. Die Aktualisierung funktioniert dabei so, dass der Quellcode der zu aktualisierenden Komponente unter /opt/regal/src per git auf den entsprechenden Branch gestellt wird. Danach wird ein neues Kompilat der Komponente erzeugt. Die aktuelle Konfiguration wird aus /opt/regal/conf genommen und es wird unter /opt/regal/apps eine neue lauffähige Version abgelegt.
Neue Versionen werden immer parallel zu alten Versionen gestartet und über einen Wechsel der Apachekonfiguration aktiviert. Erst danach wird die alte Version heruntergefahren.
Der komplette Aktualisierungsprozess erfolgt automatisch. Die alte Version bleibt immer auf dem Server liegen, so dass bei Bedarf wieder zurück gewechselt werden kann.
6.1.2. Tomcat-Applikation
Es wird ein war-Container erzeugt und im Tomcat hot-deployed.
6.1.3. Drupal-Module
Beinhaltet die Aktualisierung ein Datenbankupdate, so wird Drupal erst in den Wartungszustand versetzt (per drush oder über die Oberfläche). Danach wird die aktualisierte Version einfach per Git geholt. Bei Datenbankupdates wird noch ein Drupal-Updateskript ausgeführt.
6.1.4. Speicherschicht
Aktualisierungen von MySQL, Elasticsearch und Fedora gehen mit einer Downtime einher.
6.2. Verzeichnisse
| Verzeichnis | Beschreibung |
|---|---|
/opt/regal |
Außer Apache2, Elasticsearch und MySQL befinden sich alle Regal-Komponenten unter diesem Verzeichnis. |
/opt/regal/apps |
Die auf |
/opt/regal/bin |
Fremdpakete wie activator, fedora, heritrix, python - weitere tomcats. |
/opt/regal/conf |
Die variables.conf und die application.conf wird von verschiedenen Komponenten verwendet. |
/opt/regal/logs |
Logfiles der Skripte und Cronjobs |
/opt/regal/src |
Alle Eigenentwicklungen oder im Quellcode modifizierten Komponenten. |
/opt/regal/var |
drupal und Datenverzeichnisse. |
6.3. Ports
| Port | Komponente |
|---|---|
80 /443 |
Apache 2 |
8080 |
fedora tomcat |
9090 |
openwayback tomcat |
9200 |
elasticsearch |
9000/9100 |
regal-api |
9001/9101 |
thumby |
9002/9102 |
etikett |
9003/9103 |
zettel |
9004/9104 |
skos-lookup |
6.4. Logs
| Komponente | Pfad |
|---|---|
Apache |
/var/log/apache2 |
Tomcat |
/opt/regal/bin/fedora/tomcat/logs |
Fedora |
/opt/regal/bin/fedora/server/logs |
Elasticsearch |
/var/log/elasticsearch |
regal-api |
/opt/regal/apps/regal-api/logs |
drupal |
/var/log/apache2 #otherhosts ! und/var/log/apache2/error.log (hier ist auch die Debugausgabe) |
MySql |
/var/log/mysql |
monit |
/var/log/monit.log |
regal-scripts |
/opt/regal/logs |
6.5. Configs
| Komponente | Pfad |
|---|---|
Apache |
/etc/apache2/sites-enabled |
Tomcat |
/opt/regal/bin/fedora/tomcat/conf |
Fedora |
/opt/regal/bin/fedora/server/conf |
Elasticsearch |
/etc/elasticsearch |
regal-api |
/opt/regal/conf enthält Konfigurationsvorschläge des Installers |
regal-api |
/opt/regal/apps/regal-api/conf |
drupal |
Konfig kann gut mit dem Tool drush überwacht werden |
Elasticsearch Plugins |
/etc/elasticsearch |
oai-pmh |
/opt/regal/bin/fedora/tomcat/webapps/dnb-unr/WEB-INF/classes/proai.properties |
monit |
/etc/monit |
6.6. Apache2
| Komponente | HTTP-Pfad | Lokaler Pfad/Proxy |
|---|---|---|
Drupal |
/ |
/opt/regal/var/drupal |
Alte Importe von Webarchiven |
/webharvests |
/data/webharvests |
Täglich generierte Datei mit Kennziffern |
/crawlreports |
/opt/regal/crawlreports |
| Komponente | HTTP-Pfad | Lokaler Pfad/Proxy |
|---|---|---|
Über wget erstellte Webarchive |
/wget-data |
/opt/regal/var/wget-data |
Über wpull erstellte Webarchive |
/wpull-data |
/opt/regal/var/wpull-data |
Über heritrix erstellte Webarchive |
/heritrix-data |
/opt/regal/var/heritrix-data |
OAI-Schnittstelle für die DNB |
/dnb-urn |
|
OAI-Schnittstelle |
/oai-pmh |
|
Deepzoomer |
/deepzoom |
|
Openwayback privat |
/wayback |
|
Openwayback öffentlich |
/weltweit |
|
Thumby |
/tools/thumby |
|
Etikett |
/tools/etikett |
|
Zettel |
/tools/zettel |
|
Elasticsearch GET |
/search |
|
Fedora |
/fedora |
|
JSON-LD Context |
/public/resources.json |
|
regal-api |
/ |
|
heritrix |
/tools/heritrix |
6.7. Matomo
Matomo wird einmal täglich per Cronjob mit Apache-Logfiles befüllt. Dabei erfolgt eine Anonymisierung. Die Logfiles verbleiben noch sieben Tage auf dem Server und werden dann annoynmisiert.
6.8. Monit
Das Tool Monit erlaubt es, den Status der Regal-Komponenten zu überwachen und Dienste ggfl. neu zu starten. Folgende Einträge können in /etc/monit/monitrc vorgenommen werden
check process apache with pidfile /var/run/apache2/apache2.pid
start program = "/etc/init.d/apache2 start" with timeout 60 seconds
stop program = "/etc/init.d/apache2 stop"
check process regal-api with pidfile /opt/regal/apps/regal-api/RUNNING_PID
start program = "/etc/init.d/regal-api start" with timeout 60 seconds
stop program = "/etc/init.d/regal-api stop"
check process tomcat6 with pidfile /var/run/tomcat6.pid
start program = "/etc/init.d/tomcat6 start" with timeout 60 seconds
stop program = "/etc/init.d/regal-api stop"
check process elasticsearch with pidfile /var/run/elasticsearch.pid
start program = "/etc/init.d/elasticsearch start" with timeout 60 seconds
stop program = "/etc/init.d/elasticsearch stop"
check process thumby with pidfile /opt/regal/apps/thumby/RUNNING_PID
start program = "/etc/init.d/thumby start" with timeout 60 seconds
stop program = "/etc/init.d/thumby stop"
check process etikett with pidfile /opt/regal/apps/etikett/RUNNING_PID
start program = "/etc/init.d/etikett start" with timeout 60 seconds
stop program = "/etc/init.d/etikett stop"
check process zettel with pidfile /opt/regal/apps/zettel/RUNNING_PID
start program = "/etc/init.d/zettel start" with timeout 60 seconds
stop program = "/etc/init.d/zettel stop"
6.9. Scripts und Cronjobs
Für das Funktionieren von Regal sind einige regal-scripts sinnvoll. Die Skripte sind sämtlich unter Github zu finden.
Die folgenden Abschnitte zeigen ein typisches Setup.
6.9.1. OAI-Providing
Der OAI-Provider läuft nicht die ganze Zeit mit, da dies Probleme gemacht hat. Er wird nur für einen bestimmten Zeitraum angestellt und dann wieder ausgestellt. Auf diese Weise liefert die OAI-Schnittstelle tagesaktuelle Daten.
0 2 * * * /opt/regal/src/regal-scripts/turnOnOaiPmhPolling.sh 0 5 * * * /opt/regal/src/regal-scripts/turnOffOaiPmhPolling.sh
6.9.2. URN-Registrierung
Die URN-Registrierung erfolgt mit einem gewissen Verzug. Das dafür zuständige Skript überprüft daher zunächst das Anlagedatum der Ressource.
05 7 * * * /opt/regal/src/regal-scripts/register_urn.sh control >> /opt/regal/regal-scripts/log/control_urn_vergabe.log 1 1 * * * /opt/regal/src/regal-scripts/register_urn.sh katalog >> /opt/regal/regal-scripts/log/katalog_update.log 1 0 * * * /opt/regal/src/regal-scripts/register_urn.sh register >> /opt/regal/regal-scripts/log/register_urn.log
6.9.3. Katalog-Aktualisierung
Das System gleicht einmal am Tag Metadaten mit dem hbz-Verbundkatalog ab und führt ggf. Aktualisierungen durch.
0 5 * * * /opt/regal/src/regal-scripts/updateAll.sh > /dev/null
6.9.4. Matomo
Matomo wird mit Apache-Logfiles befüllt. Innerhalb von Matomo werden die Einträge annonymisiert.
0 1 * * * /opt/regal/regal-scripts/import-logfiles.sh >/dev/null
6.9.5. Logfile Annonymisierung
Apache-Logfiles werden sieben Tage unverändert aufbewahrt. Danach erfolgt eine Annonymisierung.
0 2 * * * /opt/regal/src/regal-scripts/depersonalize-apache-logs.sh
6.9.6. Webgatherer
Der Webgatherer prüft Archivierungsintervalle von Webpages und stößt bei Bedarf die Erzeugung eines neuen Snapshots/Version an.
0 20 * * * /opt/regal/src/regal-scripts/runGatherer.sh >> /opt/regal/regal-scripts/log/runGatherer.log # Auswertung des letzten Webgatherer-Laufs 0 21 * * * /opt/regal/src/regal-scripts/evalWebgatherer.sh >> /opt/regal/regal-scripts/log/runGatherer.log # Crawl Reports 0 22 * * * /opt/regal/src/regal-scripts/crawlReport.sh >> /opt/regal/logs/crawlReport.log
6.9.7. Backup
MySQL und Elasticsearch
Der Elasticsearch-Index und die MySQL-Datenbanken werden täglich gesichert. Es werden Backups der letzten 30 Tage aufbewahrt. Ältere Backups werden von der Platte gelöscht.
0 2 * * * /opt/regal/src/regal-scripts/backup-es.sh -c >> /opt/regal/logs/backup-es.log 2>&1 30 2 * * * /opt/regal/src/regal-scripts/backup-es.sh -b >> /opt/regal/logs/backup-es.log 2>&1 0 2 * * * /opt/regal/src/regal-scripts/backup-db.sh -c >> /opt/regal/logs/backup-db.log 2>&1 30 2 * * * /opt/regal/src/regal-scripts/backup-db.sh -b >> /opt/regal/logs/backup-db.log 2>&1
6.9.8. Entwicklung
Für die Entwicklung an Regal empfiehlt sich folgende Vorgehensweise…
7. Dokumentation
Diese Dokumentation ist mit asciidoc geschrieben und wurde mit asciidoctor in HTML übersetzt. Dazu wurde das foundation.css Stylesheet aus dem asciidoctor-stylesheet-factory Repository verwendet.
Die Schritte, um an der Doku zu arbeiten sind folgenden
7.1. Dieses Repo herunterladen
git clone https://github.com/jschnasse/Regal
7.2. Asciidoctor und Asciidoctor-Stylesheets installieren
gpg --keyserver hkp://pool.sks-keyservers.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB \curl -sSL https://get.rvm.io | sudo bash -s stable --ruby #login again sudo apt-get install bundler sudo apt-get install gem git clone https://github.com/asciidoctor/asciidoctor git clone https://github.com/asciidoctor/asciidoctor-stylesheet-factory cd asciidoctor sudo gem install asciidoctor cd ../asciidoctor-stylesheet-factory bundle install compass compile
7.3. Doku modifizieren und in HTML übersetzen
cd Regal/doc editor regal.asciidoc asciidoctor -astylesheet=foundation.css -astylesdir=../../asciidoctor-stylesheet-factory/stylesheets regal.asciidoc
8. License

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
9. Links
9.1. Slides
-
Lobid - http://hbz.github.io/slides/
-
Skos-Lookup - http://hbz.github.io/slides/siit-170511/#/